Extending Bddify
In my previous post I introduced Bddify Framework: a small yet powerful and extensible BDD framework for .Net developers. In this post I will discuss how Bddify core handles everything through its extensions and how easily you can extend it.
(You may want to first read my previous post about Bddify usage as this post is based on the material presented there.)
A closer look at the framework
In the ‘RunMe.cs’ file provided as part of Bddify package there are a few samples that showcase Bddify. Each sample is a class that represents a scenario and each scenario contains one test method that contains only one line of code:
this.Bddify();
This line “Bddifies” your object instance. The ‘Bddify’ method called here is an extension method (you can find in the ‘Bddify.cs’ file) that is provided as part of Bddify NuGet Package. Below is what ‘Bddify.cs’ contains:
public static class BddifyExtension
{
public static void Bddify(this object testObject)
{
var exceptionHandler = new ExceptionHandler(Assert.Inconclusive);
testObject.Bddify(exceptionHandler);
}
}
The extension method instantiates an ExceptionHandler class and calls an extension method on the test object passing the exception handler instance as the argument. In other words Bddify extension method in ‘Bddify.cs’ itself calls another extension method called ‘Bddify’ where the latter is implemented in the framework (in the ‘BddifyExtension.cs’ file underneath Bddify\Core), and this is the Bddify method in the core:
public static void Bddify(this object testObject, IExceptionHandler exceptionHandler = null)
{
var bddifier = LazyBddify(testObject, exceptionHandler);
bddifier.Run();
}
public static Bddifier LazyBddify(this object testObject, IExceptionHandler exceptionHandler = null, bool htmlReport = true, bool consoleReport = true)
{
var processors = new List<IProcessor> {new TestRunner()};
if(consoleReport)
processors.Add(new ConsoleReporter());
if(htmlReport)
processors.Add(new HtmlReporter());
if (exceptionHandler != null)
processors.Add(exceptionHandler);
return new Bddifier(testObject, new DefaultMethodNameScanner(), processors);
}
‘LazyBddify’ instantiates Bddifier based on the provided arguments and some conventions and returns the instance. The Bddifier class itself has only one method on it called Run which is called by Bddify method one level up the call stack.
Bddifier is the core class of Bddify framework and it barely contains any logic:
public Bddifier(object testObject, IScanner scanner, IEnumerable<IProcessor> processors)
{
_processors = processors;
_testObject = testObject;
_scanner = scanner;
}
public void Run()
{
foreach (var scenario in _scanner.Scan(_testObject))
{
//run processors in the right order regardless of the order they are provided to the Bddifer
foreach (var processor in _processors.OrderBy(p => (int)p.ProcessType))
processor.Process(scenario);
}
}
The constructors sets some fields and ‘Run’, the only method, calls Scan method on IScanner and then runs provided processors on each scenario. So all you need to extend Bddify is to customize the existing classes or provide your own scanner and/or processors.
Ok - that was a bit dry; but knowing how these all hang together helps more easily extend the framework.
IScanner
Bddify uses a scanner to scan the test object and fetch scenario(s) and steps from it. IScanner interface simply returns a list of scenarios found on the test object while each scenario contains a list of steps:
public interface IScanner
{
IEnumerable<Scenario> Scan(object testObject);
}
Two scanners are provided in the framework: MethodNameScanner and ExecutableAttributeScanner. MethodNameScanner is what I expect used most; but if you do not follow any naming convention in your tests then ExecutableAttributeScanner could be very useful.
MethodNameScanner uses reflection to read the object methods and then using some patterns it extracts scenario steps from the scanned class’s methods. DefaultMethodNameScanner is a sub-class of MethodNameScanner that scans your class for some of the common naming conventions out there:
public class DefaultMethodNameScanner : MethodNameScanner
{
public DefaultMethodNameScanner()
: base(new[]{
new MethodNameMatcher(s => s.EndsWith("Context", StringComparison.OrdinalIgnoreCase), false),
new MethodNameMatcher(s => s.Equals("Setup", StringComparison.OrdinalIgnoreCase), false),
new MethodNameMatcher(s => s.StartsWith("Given", StringComparison.OrdinalIgnoreCase), false),
new MethodNameMatcher(s => s.StartsWith("AndGiven", StringComparison.OrdinalIgnoreCase), false),
new MethodNameMatcher(s => s.StartsWith("When", StringComparison.OrdinalIgnoreCase), false),
new MethodNameMatcher(s => s.StartsWith("AndWhen", StringComparison.OrdinalIgnoreCase), false),
new MethodNameMatcher(s => s.StartsWith("Then", StringComparison.OrdinalIgnoreCase), true),
new MethodNameMatcher(s => s.StartsWith("And", StringComparison.OrdinalIgnoreCase), true)
})
{
}
}
This basically means that for every method in the test object:
- If the method name ends with the word ‘Context’ then add it as a non-asserting step.
- If the method is named ‘Setup’ then add it as a non-asserting step.
- If the method name starts with ‘Then’ then add it as an asserting step.
- If the method name starts with ‘And’ then add it as an asserting step.
- and so on and so forth.
The order of MethodNameMatcher arguments is important as that is the order the steps get added to the scenario and will later be run. Also worth noting is that if a method satisfies one of the matchers it will be ignored for the rest.
This default naming convention caters for ‘Given, When, Then’ and ‘Context/Specification’ BDD flavors. If you have a different naming convention then it should be very easy to create your own MethodNameScanner and pass it to Bddifier. An example of a custom scanner would look like:
public class AnotherMethodNameScanner : MethodNameScanner
{
public AnotherMethodNameScanner()
: base(new[]
{
new MethodNameMatcher(s => s.Equals("RunsFirstButDoesNotReportMethod", StringComparison.Ordinal), false, shouldReport:false),
new MethodNameMatcher(s => s.StartsWith("When_", StringComparison.Ordinal), false),
new MethodNameMatcher(s => s.StartsWith("ItShould_", StringComparison.Ordinal), true)
})
{
}
}
In this sample the scanner only looks for three methods on the class:
- A method named ‘RunsFirstButDoesNotReportMethod’: this method should not assert and it is not included in any of the reports even though it is run (if present).
- Methods starting with ‘When_’: these methods are not asserting; but they are reported.
- Methods starting with ‘ItShould_’: these methods are the asserting methods and they are reported.
As mentioned before, the methods, if found, are run in the order the MethodNameMatcher are provided.
You do not have to sub-class any of the existing scanners to provide your own. Bddify is happy as long as your class implements IScanner. You may also want to take advantage of ‘DefaultScannerBase’. This class scans the test object for scenarios using ‘RunScenarioWithArgsAttribute’ and takes care of scenario isolation; but allows you to fill in the steps by implementing the following abstract method:
abstract protected IEnumerable<ExecutionStep> ScanForSteps();
Both MethodNameScanner and ExecutableAttributeScanner inherit from this class.
Custom “Bddify” extension method
Let’s change the Bddify method in the ‘Bddify.cs’ file to use our new scanner:
public static void Bddify(this object testObject)
{
new Bddifier(
testObject,
new AnotherMethodNameScanner(),
new IProcessor[]
{
new ExceptionHandler(Assert.Inconclusive),
new HtmlReporter()
})
.Run();
}
This extension method uses AnotherMethodNameScanner for scanning the test object for scenarios and steps and uses built-in HtmlReporter for reporting. Compared to the built-in Bddify method this is missing the test runner, exception handler and console reporter! This means that using this extension method the tests will not be run and no console report will be generated; but the html report will still be generated. Let’s run the ‘RunMe’ tests and look at the generated html report:
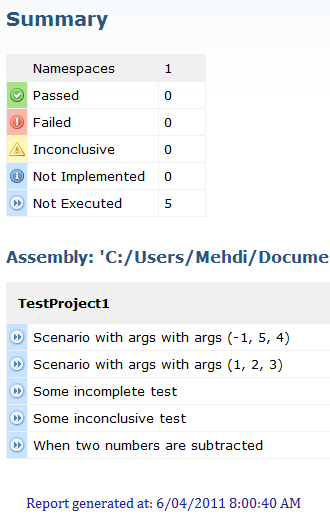
Note that none of the tests have been executed. This is indicated in the summary and in the details table. Also if you click on the scenarios you can see that none of them have any steps; that is because the new scanner does not match any of the methods in the RunMe samples.
IProcessor
Bddifier class takes an array of IProcessors in the constructor. So far we have been passing in the existing processors; but let’s have a look at IProcessor to see what it takes to create a new one:
public interface IProcessor
{
ProcessType ProcessType { get; }
void Process(Scenario scenario);
}
// copied here from another file for your reference
public enum ProcessType
{
Firstly = 1,
Execute = 2,
BeforeReport = 3,
Report = 4,
BeforeHandleException = 5,
HandleExceptions = 6
}
It has a method that processes the scenario (whatever that means) and a property called ProcessType that indicates what sort of processor Bddifier is dealing with. ProcessType works only as an ordering mechanism to make sure provided processors are run in the correct order. There is no ‘Finally’ process type, in case you are wondering, because in handling exceptions an exception may be thrown intentionally that aborts the pipeline.
Let’s write a simple processor. I will write a new reporter that exports the result into an Excel file. This way we can more easily analyse the result and create graphs based on the test results.
using System;
using System.Collections.Generic;
using Bddify.Core;
public class ExcelExporter : IProcessor
{
static readonly List<Scenario> Scenarios = new List<Scenario>();
public ProcessType ProcessType
{
get { return ProcessType.Report; }
}
static ExcelExporter()
{
AppDomain.CurrentDomain.DomainUnload += CurrentDomain_DomainUnload;
}
static void CurrentDomain_DomainUnload(object sender, EventArgs e)
{
// run this only once when the appdomain is unloading, that is when the last test is run
GenerateHtmlReport();
}
internal static void GenerateHtmlReport()
{
// DIY :)
// ToDo: Create the file, create the spreadsheet, run through the scenarios and add them to the spreadsheet
// For each scenario run through its steps and add them along with their result underneath each scenario
// layout the result in an easy to read and analyse way
}
public void Process(Scenario scenario)
{
Scenarios.Add(scenario);
}
}
Ok - I was going to implement this; but I thought this post is about how to extend bddify and not how to create and populate an excel spreadsheet using c#. This however should provide a good foundation for your implementation.
One thing you may note in the implementation is that I am not writing the report in the ‘Process’ method - instead I add the scenario to a list that gets processed at the end of the test run session. This way I avoid IO operations during test runs which leads to a performance boost. Also you can avoid complicated file manipulation; e.g. if file does not exist, create it and add a header; otherwise open it; then find the last row and so on and so forth.
Of course you would have to provide this extension to bddifier - your extension method could look like:
public static void BddifyWithExcelExporter(this object testObject)
{
new Bddifier(
testObject,
new AnotherMethodNameScanner(),
new IProcessor[]
{
new TestRunner(),
new ExcelExporter()
})
.Run();
}
TestRunner and ExceptionHandler are other built-in processors with process type Execute and HandleException accordingly. Bddifier does not really care what your processor does: it only sees a processor as a node in the processors’ pipeline and calls it in turn passing in the scenario. In your processor, you may make changes to the scenario and/or execute some methods on it (which is what TestRunner does), generate some reports off it (which is what reporters do), throw some exception (which is what ExceptionHandler does) or do anything else you desire.
The extension points discussed in this article are main extension points; but there are smaller customisations you can achieve by sub-classing some of the existing classes and overriding their virtual methods which I will not bore you with here.
The small extensions I coded as part of this article can be downloaded from here.
Hope this helps.